
转载声明:文章来源 https://blog.csdn.net/leasonw/article/details/78009402
一、基本知识
字典树(TrieTree),又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。
典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
它有3个基本性质:
1、根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2、从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3、每个节点的所有子节点包含的字符都不相同。
二、构建TrieTree
给定多个字符串,如 {banana,band,apple,apt,bbc,app,ba},那么所构建的一棵TrieTree形状如下: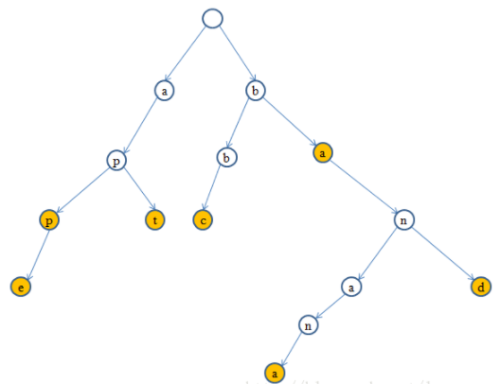
其中,黄色的节点代表从根节点通往该节点的路径上所经过的节点的字符构成的一个字符串出现在原来的输入文本中,如以d为例,路径上的字符为:b-a-n-d,对应输入的字符串集合中的”band”。
TrieTree可以很方便的扩展,当来了新的字符串时,只要把新的字符串按照原本的规则插入到原来的树中,便可以得到新的树。
如需要加入新的单词”bat”,那么树的结构只需简单的拓展成如下的形式:
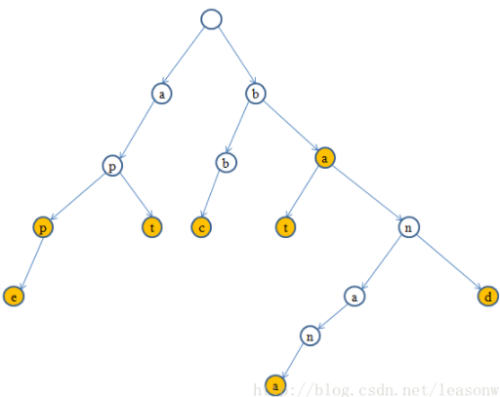
可以看出,TrieTree充分利用字符串与字符串间拥有公共前缀的特性,而这种特性在字符串的检索与词频统计中会发挥重要的作用。
三、利用TrieTree进行字符串检索
利用上一节中构造的TrieTree,我们可以很方便的检索一个单词是否出现在原来的字符串集合中。
例如,我们检索单词”banana”,那么我们从根节点开始,逐层深入,由路径b-a-n-a-n-a最终到达节点a,可以看出此时的节点a是黄色的,
意味着“从根节点到该节点的路径形成的字符串出现在原来的字符串集合中”,
因此单词”banana”的检索是成功的。
又如,检索单词”application”,从根节点沿路径a-p-p,到达节点p后,由于节点p的后代并没有’l’,这也意味着检索失败。
再举一个例子,检索单词”ban”,沿着路径b-a-n到达节点n,然而,当前的节点n并不是黄色的,说明了“从根节点到该节点的路径形成的字符串“ban”没有出现在原来的字符串集合中,但该字符串是原字符串集合中某个(些)单词的前缀”。
可以看出,利用TrieTree进行文本串的单词统计十分方便,当我们要检索一个单词的词频时,不用再去遍历原来的文本串,从而实现高效的检索。这在搜索引擎中统计高频的词汇是十分有效的。
四、TrieTree的代码实现
以下为以C++语言实现的TrieTree数据结构。
#include<vector>
#include<string>
#include<cassert>
#include<fstream>
#include<algorithm>
#include<stack>
#include<map>
using namespace std;
#define MAX_SIZE 26 //字符集的大小,这里默认字符都是小写英文字母
struct TrieTreeNode{
int WordCount; //用于记录以该节点结尾的单词出现的次数
int PrefixCount; //用于记录以该节点结尾的前缀出现的次数
char ch; //该节点的字符值
TrieTreeNode* parent; //指向的父节点指针,一般来说不需要,但为了后面高效的遍历树并统计词频所增加的
TrieTreeNode** child; //指向孩子的指针数组
TrieTreeNode(){
WordCount = 0;
PrefixCount = 0;
child = new TrieTreeNode*[MAX_SIZE];
parent = NULL;
for (int i = 0; i < MAX_SIZE; ++i)
child[i] = NULL;
}
};
class TrieTree{
private:
TrieTreeNode* _root;
public:
//构造函数
TrieTree(){ _root = new TrieTreeNode();
}
//向树插入新单词
void insert(const string& word){
if (word.length() == 0) { return; }
insert_I(_root, word);
}
//给定某个单词,返回其在文本中出现的次数
int findCount(const string& word){
if (word.length() == 0){ return -1; }
return findCount_I(_root, word);
}
//给定某个前缀,返回其在文本中出现的次数
int findPrefix(const string& prefix){
if (prefix.length() == 0) return -1;
return findPrefix_I(_root, prefix);
}
//统计文本中出现的所有单词及出现的次数
map<string, int> WordFrequency(){
map<string, int> tank;
countFrequency(_root, tank);
return tank;
}
private:
pair<string, int> getWordCountAtNode(TrieTreeNode* p){
int count = p->WordCount;
string word;
stack<char> S;
do{
S.push(p->ch);
p = p->parent;
} while (p->parent);
while (!S.empty()){
word.push_back(S.top());
S.pop();
}
return {word,count};
}
void countFrequency(TrieTreeNode* p,map<string, int>& tank){
if (p == NULL) return;
if (p->WordCount > 0) tank.insert(getWordCountAtNode(p));
for (int i = 0; i < MAX_SIZE; ++i){
countFrequency(p->child[i], tank);
}
}
void insert_I(TrieTreeNode* p, const string& word){
for (int i = 0; i < word.length(); ++i){
int pos = word[i] - 'a';
if (p->child[pos] == NULL){
p->child[pos] = new TrieTreeNode();
p->child[pos]->ch = word[i];
p->child[pos]->parent = p;
}
p->child[pos]->PrefixCount++;
p = p->child[pos];
}
p->WordCount++;
}
int findCount_I(TrieTreeNode* p, const string& word){
for (int i = 0; i < word.length(); ++i){
int pos = word[i] - 'a';
if (p->child[pos] == NULL) return 0;
p = p->child[pos];
}
return p->WordCount;
}
int findPrefix_I(TrieTreeNode* p, const string& prefix){
for (int i = 0; i < prefix.length(); ++i){
int pos = prefix[i] - 'a';
if (p->child[pos] == NULL) return 0;
p = p->child[pos];
}
return p->PrefixCount;
}
};五、TrieTree的应用
利用TrieTree检索单词是否出现在文本中:
例如,有一文本内容如下:
the apple apple banana potato potato. potato apple
oppo potato, apple tomato the.
定义一个类FileReader用来读取文本文件:
class FileReader{
private:
vector<string> text;
string erase;
bool erase_flag;
public:
FileReader():erase_flag(false){}
void read(const string& filename){
ifstream infile;
infile.open(filename.data());
assert(infile.is_open());
string word;
while (infile>>word){
if (erase_flag){
for (int i = 0; i < erase.length(); ++i){
int n = 0,pos=0;
while (n<word.length())
{
pos=word.find(erase[i], pos);
if (pos < 0) break;
else{
word.erase(pos, 1);
}
}
}
text.push_back(word);
}
}
}
void InputEraseChar(const string& CharSet){
if (CharSet.length() == 0) return;
erase = CharSet;
}
void OnEraseChar(){ erase_flag = true; }
void OffEraseChar(){ erase_flag = false; }
void clearData(){
text.clear();
}
void writeData(){
if (text.size() == 0) { printf("No Data!!"); return; }
for (int i = 0; i < text.size(); ++i){
printf("%s ", text[i].data());
}
}
vector<string> outputData(){
if (text.size() == 0) return{};
vector<string> output(text);
return output;
}
private:
bool IsEraseChar(const char &ch){
return erase.find(ch);
}
};测试1:统计某些单词或前缀出现次数
主函数入口如下:
int main(){
FileReader reader;
reader.InputEraseChar(",.");
reader.OnEraseChar();
reader.read("F:\\TrieTreeTest.txt");
vector<string> words = reader.outputData();
TrieTree tree;
for (int i = 0; i < words.size(); ++i)
tree.insert(words[i]);
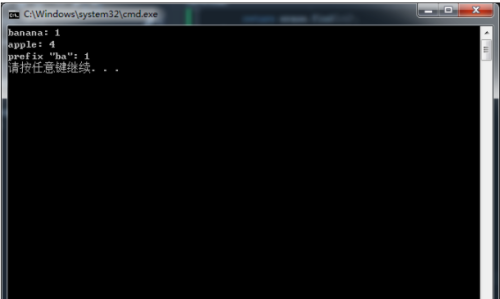
int count=tree.findCount("banana");
printf("banana: %d\n",count);
count=tree.findCount("apple");
printf("apple: %d\n",count);
int prefixCount=tree.find("ba");
printf("prefix \"ba\": %d\n",prefixCount);
return 0;
}程序输出如下:
测试2:统计所有出现过的单词词频
int main(){
FileReader reader;
reader.InputEraseChar(",.");
reader.OnEraseChar();
reader.read("F:\\TrieTreeTest.txt");
vector<string> words = reader.outputData();
TrieTree tree;
for (int i = 0; i < words.size(); ++i)
tree.insert(words[i]);
map<string, int> tank = tree.WordFrequency();
map<string, int>::iterator begin = tank.begin();
for (; begin != tank.end(); ++begin){
printf("%s: %d\n", begin->first.c_str(), begin->second);
}
return 0;
}代码结果如下:
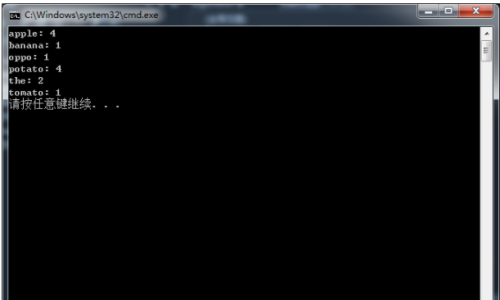
以上就是TrieTree结构在文本中统计单词词频的应用。




帖子还没人回复快来抢沙发